
Google, Bing and GEO : who is right?
For a while, as the debate among digital marketing professionals raged over the scope of GEO (Generative Engine Optimization) and AEO (Answer Engine Optimization) – and over how far these disciplines differed from or overlapped with traditional SEO – Google and Bing had essentially avoided taking a structured position. Scattered communications, spokesperson statements, podcasts: nothing organic.
In these early months of 2026, something has changed. Both engines have published documents of some substance that attempt to define their point of view on the topic. For a professional in the field, used to navigating a hazy landscape where facts are scarce and opinions (some of them nonsense) abound, this is valuable material – provided you read it with the necessary critical attention. Because, as we’ll see, the picture that emerges is anything but uniform.
Bing: grounding and search are different systems
The article published on the Bing blog on 6 May 2026, authored by Krishna Madhavan, Knut Risvik and Meenaz Merchant, has a title that already points the way: Evolving role of the index: From ranking pages to supporting answers. The subtitle clarifies: Same Foundations. Different Optimization Problems.
The central thesis is that traditional search and grounding for AI systems share the same underlying infrastructure – crawling, indexing, quality signals – but are optimized for fundamentally different ends. Traditional search answers the question “which pages should the user visit?”; grounding answers a different question: “what information can an AI system responsibly use to build an answer?” According to the authors, the two questions resemble each other, but are not the same thing.
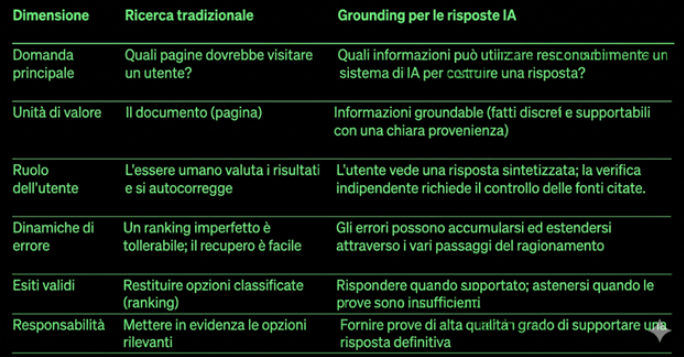
The unit of value changes: in traditional search it is the document in its entirety, a page a human can scroll, evaluate and act on; in grounding it is the groundable piece of information, a discrete, verifiable fact with a clear provenance. This shift in perspective has concrete implications for index quality metrics: in traditional search a stale result is a ranking problem; in grounding a stale fact directly produces a wrong answer. In search the error is tolerable because the user can self-correct; in grounding the error can propagate through the model’s reasoning steps without anyone noticing in real time.
Another substantial difference concerns contradictions between sources: while a traditional engine can rank one source above another, leaving the user to arbitrate, a grounding system cannot afford to silently arbitrate between contradictory sources, because an AI model doing so could confidently assert the wrong thing, without the user having any way to notice before receiving the answer.
It’s worth stressing that the Bing document does not deny the centrality of traditional SEO as a foundation – on the contrary, it explicitly states that grounding is built on top of the same infrastructure. But it acknowledges that, above that common foundation, there exists a distinct optimization layer, with its own metrics and different responsibilities. It’s a nuanced position, but the distinction is sharp.
Google: good SEO is good GEO
Google’s position is, at least in its official communications, noticeably different. The Search team’s long-standing spokesperson, Danny Sullivan, has repeatedly reiterated – including in the episode of Search Off The Record picked up by Search Engine Journal – that good SEO is good GEO, and that professionals don’t need to worry about adapting their content specifically for AI systems. John Mueller has expressed analogous positions.
This line then found official formalization in the documentation page Optimizing your website for generative AI features on Google Search, updated on 15 May 2026, which for the first time brings together the Search team’s point of view in an organic way. The most relevant – and most commented-on – section is the one dedicated to mythbusting, in which Google explicitly dismantles some of the most widespread practices in the GEO debate.
The llms.txt file is dismissed as unnecessary: there’s no need to create new machine-readable files, AI markup or Markdown to appear in generative search features. Content chunking is likewise discouraged: Google’s systems would be able to understand the nuances of multiple topics on a single page and surface the relevant segment to the user. Rewriting content for AI systems is deemed useless: AI models understand synonyms and general meanings without the need for specific optimizations. Finally, structured data is downplayed: it would not be required for generative search, and no special schema.org markup would exist to add.

On the content front, the line is equally clear-cut. Sullivan has explicitly identified so-called commodity content – generic, interchangeable content – as the category that suffers most in the era of AI Mode and AI Overview, because it can no longer generate the same click-driving capacity it once did. AI systems analyze a variety of sources and reward those who bring a unique, non-replicable point of view: content based on direct experience is systematically worth more than a summary of what is already available elsewhere. It’s not the certified death of a format, but a growing structural pressure that content producers cannot afford to ignore. The Search team’s underlying message remains: keep doing good SEO, focus on content that is useful and relevant to users, and the rest will follow.
The voice out of the chorus: when Google doesn’t speak with one voice
Here the picture gets interestingly complicated. On 11 April 2026, Addy Osmani – a Google engineer working on Google Cloud and Gemini, and a long-time developer advocate – published on his personal blog an article titled Agentic Engine Optimization (AEO) that maps out an optimization path for AI agents in contradiction, almost point by point, with the Search team’s official page.
Osmani defines AEO as the practice of structuring, formatting and serving technical content so that AI agents can actually use it. Among his recommendations: implement llms.txt as “a sitemap for AI agents”; structure content for machine scanning, not just human reading; treat token count as a primary documentation metric; adopt skill.md files to signal an API’s capabilities to agents; ensure that robots.txt doesn’t inadvertently block AI crawlers.
Osmani’s argument starts from an empirical observation: when an AI agent accesses documentation, the entire multi-page navigation a human user would do over minutes compresses into one or two HTTP requests. The concept of the “user journey” collapses into a single server-side event. Everything that matters in traditional analytics systems – scroll depth, time on page, link clicks, tutorial completion – becomes invisible. The agent was there, read the content, and based on how it was structured either completed the task successfully or produced a wrong solution because the content was too heavy in token terms, badly structured, or blocked by a misconfigured robots.txt.
While this article was awaiting publication, a further official Google voice “in favor” of llms.txt was added on 20 May, when llms.txt became one of the elements that help improve the score of Lighthouse’s “Agentic Browsing” audit. Its implementation is, moreover, explicitly recommended in Chrome’s official documentation.
It would, however, be a mistake to read this as a leak of confidential information or as an act of deliberate dissent. Anyone who knows the dynamics of a company as complex as Google is well aware that its teams don’t always talk to each other in a coordinated way: it has happened before with the handling of SPAs, with the issue of back-button hijacking and with AdSense policies, where officially different positions coexisted simultaneously across different departments without this necessarily representing an intentional contradiction. Osmani speaks from the perspective of someone working on agentic systems and on Gemini; Sullivan speaks from the Search team’s perspective. They are two legitimate observers of a complex reality, with different angles and different organizational priorities. Nor can it be ruled out that a degree of ambiguity is also functional for Google itself: avoiding committing too early to a technical standard that is still evolving is a rational choice for a company operating in a market that changes this fast.
The consultant’s dilemma
The dream of every SEO professional working on complex projects is to be able to ground their recommendations in clear, uncontested official best practices. If Google’s guidelines state that implementing llms.txt is useful, the consultant can propose it without reservation. If Google states instead that it’s useless, the consultant should be able to leave it out of the work plan just as serenely.
But when the Search team’s official page says one thing and a Google engineer working daily on AI systems says the opposite, the situation gets complicated. And it gets even more complicated for a practical reason: any client, today, can open ChatGPT, Gemini or any other conversational model and ask whether their site is optimized for AI answer engines. The answer they receive will not only probably recommend implementing the llms.txt file, but may also suggest the llms-full.txt version, skill.md files for APIs, a token optimization strategy for documentation – everything Google’s Search team explicitly says to ignore.
It’s not an insurmountable problem for a well-prepared professional. But it’s a conversation that shouldn’t be necessary, and one that requires a level of up-to-date knowledge and argumentative clarity that, in a more coherent landscape, would simply be superfluous. Uncertainty is nothing new in our field; this one, however, has the distinctive feature of coming from the inside, from the overabundance of authoritative voices that don’t converge.
What we can distill
Putting together the available indications – Google’s official ones, Bing’s, Osmani’s, mindful of their respective vantage points – it’s possible to identify a few points of real convergence to orient ourselves around with reasonable confidence.
The first is that the SEO Foundation remains central. On this, Google, Bing and Osmani agree without reservation: a technically solid site, with quality content, well indexed and with a clear structure, is the starting point both for visibility in traditional search and for visibility in AI grounding systems. Those who have built solid SEO over the years don’t need to start from scratch.
The second point of convergence concerns the quality and uniqueness of content. The growing pressure on commodity content is not just an editorial wish: it’s a consequence of the way grounding systems select and weight sources, favoring those with clear provenance, verifiable facts and points of view that can’t be replicated elsewhere. Bing says it from the infrastructure side; Google says it from the editorial strategy side. The signal is coherent.
The third point – and here positions diverge – concerns technical interventions specific to AI systems. Bing invites us to think of optimization for grounding as a layer added on top of traditional SEO. Osmani proposes a full-fledged stack of interventions (llms.txt, robots.txt audit, token count, skill.md). Google’s Search team says to ignore all of this. In the absence of definitive certainties, the most pragmatic position is to evaluate case by case: on sites with structured technical documentation and AI-agent traffic already measurable in server logs, AEO interventions have a concrete, verifiable logic. On editorial sites or general e-commerce, the priority remains well-executed SEO.
Three responsibilities no one wants to take on
Ours, as professionals
Building a solid professional position in a scenario of uncertainty does not mean waiting for guidelines to converge – that might not happen, or might happen too late. It means grounding your recommendations in your own evidence: monitoring AI-agent traffic in server logs, testing the effects of technical interventions on sites that allow it, documenting the results. This is not the mantra of “test and verify” as a generic answer to uncertainty; it’s the building of a body of proprietary data that lets you make your case to the client independently of what Google, Bing or ChatGPT say.
It’s worth adding that relying blindly on Google’s official statements has never been a robust strategy, and it isn’t now. Not out of generalized cynicism, but because there is a documented history of public communications diverging from the actual mechanisms on specific topics. The use of click data for ranking was publicly denied for years, until the U.S. Department of Justice antitrust proceedings brought to light the internal instruction to employees not to discuss it externally, and Pandu Nayak’s sworn testimony confirmed NavBoost’s central role. Likewise for Chrome data. These precedents don’t concern llms.txt – the stakes are different – but they concern exactly the theme of this article: how Google communicates externally about how its own systems work. They justify critical reading, not systematic suspicion.
Google and Bing’s
The divergence between the two engines is manageable: professionals are used to working with misaligned signals. The more acute problem is internal to Google, and its solution doesn’t require a single corporate voice – that would be unrealistic – but official documents that explicitly acknowledge the limits of their own scope of applicability. A mythbusting page calibrated on the general use case is useful; it becomes misleading when it’s read as valid for all contexts, including those it wasn’t designed for.
Standalone AI models’
This is the least discussed responsibility and probably the most urgent in the short term. A conversational model that answers questions about optimizing for AI search without explicitly flagging that the available recommendations are divergent and contested is not offering a useful service: it’s collapsing an open debate into a closed answer. This isn’t a matter of censorship or of taking sides between Sullivan and Osmani. It’s a matter of epistemic honesty toward the end user.
The end point of this landscape can’t be predicted with certainty. But the direction is clear enough: search engines and AI systems are evolving toward architectures in which the distinction between “indexing to display” and “retrieving to answer” becomes increasingly relevant. Those who work in this field can’t afford to wait for guidelines to stabilize before building their own position. Guidelines always arrive after the facts – and that is exactly why professionals exist.
Did you find this article useful? Read also
More articles in AI & SEO
Markdown for AI Agents: the new language of the web
Markdown for AI agents: the web’s new language The web has always been built for human beings. HTML pages loaded with menus, scripts, advertising banners, tracking tags: everything designed for a browser...
Read
Prompt Analysis: a new world to explore
Prompt analysis: a new world to explore Search analysis was born as a tactical tool for ranking on search engines. With the advent of chatbots and large language models, the raw material...
Read
The impact of AI Overview on People Also Ask answers
The impact of AI Overview on People Also Ask answers People Also Ask boxes first appeared in Google's results in the United States in 2015. After an initial phase of testing and...
Read
Technical GEO: Discoverability, Accessibility and Readability
Technical GEO: Discoverability, Accessibility and Readability Rewriting the Rules of the Game in the AI Era The revolution sparked by Large Language Models (LLMs) is radically reshaping the dynamics of online search,...
Read
Google Search Console and Bing Webmaster Tools: Governing Access to Your Data
Google Search Console and Bing Webmaster Tools: Governing Access to Your Data Saying we need to pay attention to who can access our organic performance data and all the other information offered...
Read
From Keywords to Prompts and Back: Bing’s AI Performance Panel
From Keywords to Prompts and Back: Bing's AI Performance Panel In the article dedicated to query fan-out and reciprocal rank fusion we looked at the mechanism by which answer engines break down...
Read