
From Keywords to Prompts and Back: Bing’s AI Performance Panel
In the article dedicated to query fan-out and reciprocal rank fusion we looked at the mechanism by which answer engines break down a user’s complex prompts into sub-queries and then retrieve the web pages from which they draw the content needed to craft their replies.
Let’s dig deeper into the subject, above all to check whether traditional SEO really is dead and keywords no longer have any value.
Many surveys confirm that the search habits of digital users have changed radically with the arrival of ChatGPT, Perplexity, Gemini, and so on. Users ask questions in natural language, using text strings far more elaborate than the good old “keywords” that for over two decades served as the guiding star of every content optimisation activity.
LLM-based engines, for their part, break down the user’s elaborate prompt into sub-queries through the fan-out mechanism and query various indexes — primarily those of Google and Bing — in order to identify the most relevant resources, draw up a final list using the RRF mechanism, and then pull information from the identified URLs through direct access to those resources.
The final responses from the LLM models are therefore assembled using the information found on the web pages that achieved the best overall relevance score across the fan-out query set.
All clear, then? Not quite.
A wealth of commercial tools — and the search engines themselves — offer a great deal of information about classic keywords. Pick any topic and we can identify macro-trends in search interest, search volumes, seasonal fluctuations and much more.
When it comes to user prompts, on the other hand, we know little to nothing. No LLM model makes data on its users’ search activity available, not even in aggregated form. The information we can glean from commercial tools or data providers via API is the result of probabilistic calculations that, however grounded in statistically relevant elements, remain estimates whose reliability is difficult to judge.
In Google’s case, AI Mode user prompts — including follow-up ones — are technically logged in Google Search Console, but it’s reasonable to assume that a significant percentage of this particular type of query ends up in the bucket of “anonymized queries“, that is, the set of searches hidden for privacy reasons. Google defines anonymised queries as “those that aren’t sent by more than a few dozen users over a two- or three-month period“. The impression and click data for these queries are included in the totals, but they disappear from the reports the moment a query filter is applied.
The Only Source of Official Data: Bing AI Performance
On close inspection, the only official data directly tied to user prompts is what’s offered by the AI Performance panel in Bing Webmaster Tools, activated in February 2026.
It’s an extremely interesting dataset, because it’s the only one that offers a clear view of how citations on Copilot and partners are trending, with the ability to filter the data both by URL and by “Grounding Queries“.
Before getting into the details, we need to clear up a preliminary doubt: Bing has a small share of the search market, and the data shown in the “Search Performance” panel is modest compared to what’s available in Google Search Console. Does the information provided in the AI Performance panel represent a statistically significant volume of data?
Below is the classic-search performance screen.
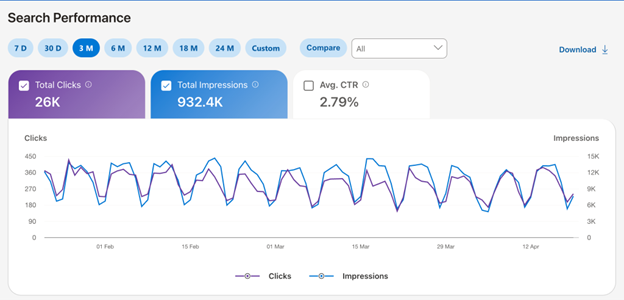
And below is the AI Performance screen for the same site and the same time range:

As you can see, the total number of citations is over a quarter of the impressions and almost 10 times higher than the clicks driven by Bing Search — a volume of information that, all proportions considered, can be regarded as significant.
Citations indicate the total number of times the site’s content has been used and visually displayed as a source (through links or textual references) within a response generated by Microsoft Copilot, in AI-generated summaries in Bing Search, and in AI integrations of selected partners.
Avg. Cited Pages, on the other hand, refers to the average number of unique pages from the site cited daily in the responses.
Just below the time-series chart showing the trend of citations and the average daily number of pages cited, the report displays the list of Grounding Queries, defined by Bing as the key phrases used by the AI to retrieve the content cited in its responses.
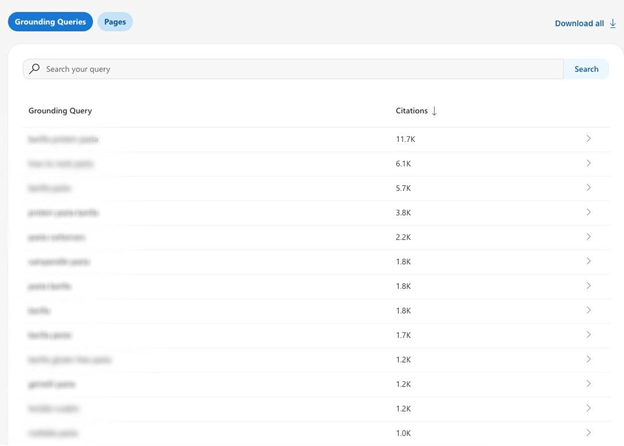
As you can see, next to the “Grounding Queries” selector there is a “Pages” one, which allows you to filter citations by URL and check which pages on our site are most frequently used by the Microsoft ecosystem’s AI to pull information for crafting responses for its users.
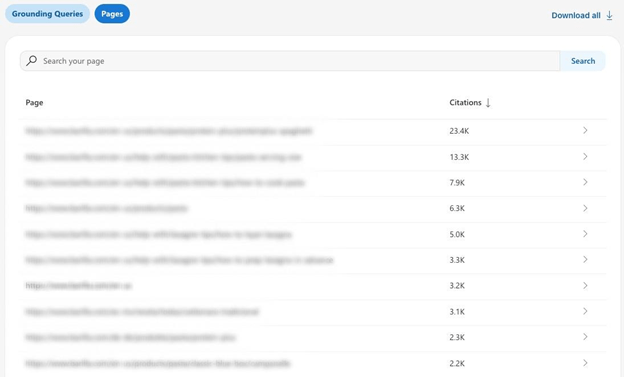
Last month Bing added the ability to filter the data by clicking on a Grounding Query, so as to display the time-series Citations data for the selected query only, along with the list of URLs cited for that specific combination.
Clicking on a page URL, on the other hand, shows beneath the chart of its Citations the Grounding Queries that drove them.
Grounding Queries: the Link Between Fan-out and Citations
We said that Grounding Queries are the key phrases the AI uses to retrieve the content cited in its responses. Described this way, they appear to correspond to the Fan-out queries used by LLM models to respond to user prompts for which a site’s pages turn out to be relevant.
If that’s the case, even though we have no way of knowing the user’s actual prompts, we do know which fan-out combinations are generating citations and we can verify whether the ones we want to target with our content optimisation activities improve their performance following our implementations.
Can we trace user prompts back from Grounding Queries? You certainly can’t reconstruct the real user prompts, but we can hypothesise the “typical” prompts associated with the grounding queries of a given URL — perhaps with the help of AI — so that we can use them to monitor our share of voice on other LLM models. On reflection, even if ChatGPT or Perplexity were to one day make their users’ search data available in some form, I’d argue they would necessarily have to provide it in aggregated form to make it intelligible and usable.
There and Back Again
Despite the evident and well-documented shift in user search habits, with people favouring elaborate, natural-language prompts, the idea of radically overturning the approach to content optimisation turns out to be without practical foundation. The query fan-out mechanism employed by LLM engines brings the focus of information retrieval back onto short, synthetic queries that describe conceptual entities and act as a connector between the user’s elaborate intent and the relevant web resources.
The AI Performance panel in Bing Webmaster Tools makes it clear in black and white that the link between a site’s content and citations in LLM responses is the Grounding Queries. These “key phrases” are, in effect, the fan-out queries that identify the target concept, and they look far more like the good old keywords than like the complex input prompts.
As a result, any GEO content-optimisation activity aimed at intercepting AI-based traffic must necessarily be grounded in analysing and optimising for Grounding Queries, in full respect of the roots of SEO — where the keystone is not natural language, but conceptual synthesis.
More articles in AI & SEO
Prompt Analysis: a new world to explore
Prompt analysis: a new world to explore Search analysis was born as a tactical tool for ranking on search engines. With the advent of chatbots and large language models, the raw material...
Read
The impact of AI Overview on People Also Ask answers
The impact of AI Overview on People Also Ask answers People Also Ask boxes first appeared in Google's results in the United States in 2015. After an initial phase of testing and...
Read
Google, Bing and GEO: who is right?
Google, Bing and GEO : who is right? For a while, as the debate among digital marketing professionals raged over the scope of GEO (Generative Engine Optimization) and AEO (Answer Engine Optimization)...
Read
Technical GEO: Discoverability, Accessibility and Readability
Technical GEO: Discoverability, Accessibility and Readability Rewriting the Rules of the Game in the AI Era The revolution sparked by Large Language Models (LLMs) is radically reshaping the dynamics of online search,...
Read
Google Search Console and Bing Webmaster Tools: Governing Access to Your Data
Google Search Console and Bing Webmaster Tools: Governing Access to Your Data Saying we need to pay attention to who can access our organic performance data and all the other information offered...
Read
AI Overview, CTR Decline and the Depth of Search Intent
Nello scorso articolo abbiamo iniziato ad analizzare l’impatto dell’AI Overview sui classici Blue Link e sui Featured Snippet, listing di diversa natura ma accomunati da una buona capacità di trasformare le impression in click nel contesto della ricerca organica su Google. In linea generale, l’impatto dell’AI Overview è stato imponente e ha segnato una vera pietra miliare nel processo di trasformazione di Google in motore di risposta, ma non tutti i settori tematici sono stati interessati da questo vero terremoto nella stessa misura. In Italia, ad esempio, dall’analisi di un panel di oltre 6 milioni di SERP da gennaio 2025 a marzo 2026 si evidenzia un impatto complessivo dell’AI Overview sui top ranking organici di poco superiore al 22%. Se si isolano i diversi territori, però, emergono scenari completamente diversi.
Read