
GEO Content Strategy and Content Optimisation
In previous articles we saw how the arrival of Answer Engines is revolutionising the dynamics of online information search, profoundly changing user behaviour and, consequently, the form and nature of the activities aimed at optimising brand visibility and relevance in this new scenario. We also saw how the different technology underlying Large Language Models (LLMs) demands a rethink of the classic best practices of technical SEO, where solutions once cleared by Google (such as those that require code execution for rendering) can now be classified as serious issues from a GEO perspective, since LLMs are equipped with less advanced crawling technology. After getting the site “in shape” on the technical side, we now turn to the impact of the GEO revolution on content strategy and content optimisation, which represent the second pillar of on-site optimisation.
Defining the content strategy
Any effective content marketing strategy must necessarily start from the analysis of the informational needs of the audience: in order to provide the right answers, it is essential to know and understand the questions of the audience you intend to reach.
While not calling this axiom into question, the arrival of Answer Engines introduces a significant challenge: the new generation of LLMs do not make their users’ search data available — or rather, their prompt data — not even in aggregated form. To devise a data-driven content strategy, however, we can turn to the billions of searches performed on traditional search engines such as Google and Bing, which make information available in granular form and provide a panel that is broadly representative.
That said, the classic keyword analysis is only a starting point. In the GEO world, keywords are replaced by search strings (prompts) that are on average far more elaborate, defining the user’s informational need more accurately. The GEO objective isn’t to fight for a position on a keyword, but to become citable, semantically clear and reliable, offering appropriate answers to the user’s prompts.
To occupy the most strategic touch-points, you need to identify the answers to those prompts where the brand isn’t generating mentions or citations (visibility and relevance). This represents the “gap to fill” — that is, the areas not properly covered. To identify these relevant prompts and obtain statistically meaningful data, you can use commercial tools such as Answer the Public, derive them from the analysis of good old keywords and their SERPs, or — a not exactly optimal solution — generate them with the help of AI. Once we have defined the prompts, all that remains is to analyse the responses from the answer engines in order to identify the areas that are not effectively covered — which will be the target of our content strategy.
Content optimisation
When creating new content, optimisation has to take into account the inner workings of Answer Engines in order to maximise the chances of being cited.
The content selection mechanisms
The process starts when a user asks a question the model can only answer by pulling information from the web. The LLM model brings the question back to a main query, which is then broken down into a certain number of sub-queries through a mechanism known as fan-out.
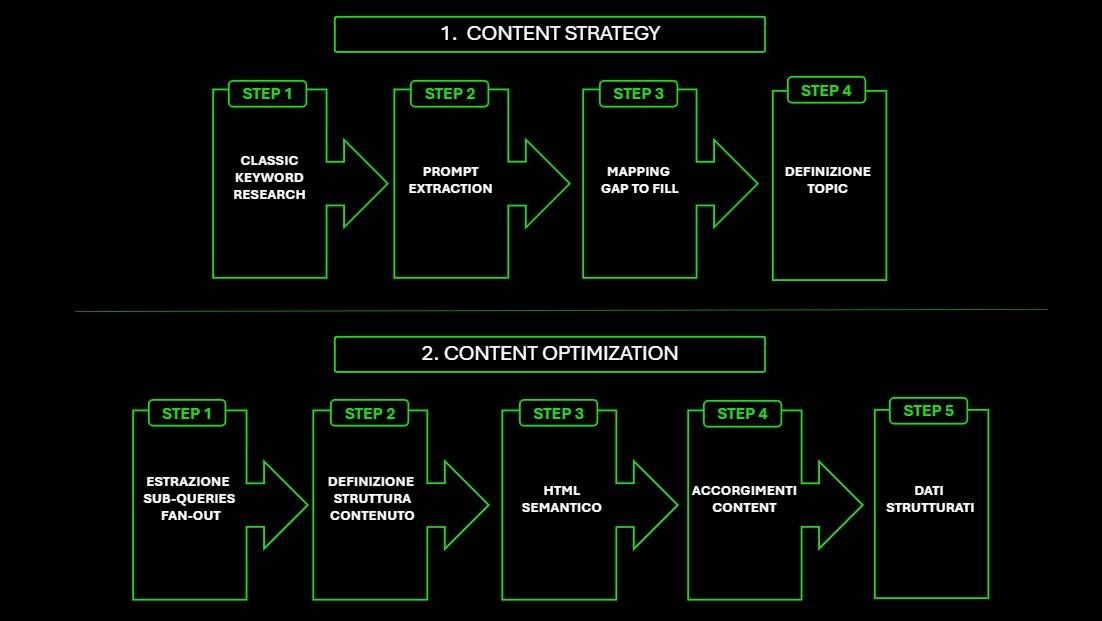
At this point, the model runs a search for answers both to the main query and to the sub-queries, retrieving a number of relevant web resources.
All the retrieved pages are then evaluated using a methodology comparable to that of Reciprocal Rank Fusion: the resources that appear multiple times in the results for the main query and its sub-queries earn a higher score, increasing the chances of obtaining mentions and citations.
Designing the structure for citation
The definition of a piece of content’s structure must take this fan-out mechanism into account. The target key, which identifies the core of the prompt’s informational need, must be broken down into sub-queries in order to identify all the conceptual elements to weave into the various paragraphs. In doing so, you increase the chances that the content is pulled into multiple intermediate search results within the LLM engine, thereby earning a higher score in the evaluation process and a greater probability of being cited or mentioned in the generated response.
Content optimisation involves the application of all the classic SEO best practices, enriched with the more specific GEO ones. In particular, it is useful for the content to be built so as to be as “ready-to-use” as possible by “conversational” engines.
Making content easy to extract
To be easily extracted and citable, content must be structured in a logical, hierarchical way. It is essential to use clear hierarchical headings (H1, H2, H3) and adequate formatting, so as to make the relationships between concepts easier to understand. According to many industry professionals, optimisation should happen at the “chunk” (fragment) level: each passage should be focused on a single concept, keeping passages semantically cohesive and self-sufficient, so that each block is understandable independently of the context of the entire page. When answering a specific question, according to this view, you should start with a direct and concise sentence, using a neutral, factual and non-promotional tone, in order to make the content easy to summarise within an answer-first response. This also requires using shorter sentences, each of which answers a single question (even if implicit), helping LLMs to extract information more clearly.
On “chunking”, however, well-known Google spokespeople have weighed in too — such as John Mueller and Danny Sullivan — who have strongly advised against fragmenting content for LLMs and suggested focusing — as ever — on the end user.
In our view, it is possible to create content of genuine value to the user while taking into account the inner workings of the software that act as the point of contact between the demand for and supply of information. In essence, when drafting our content we will try to follow a linear path, clearly delineating the conceptual units that make up our topic and avoiding any excess of either fragmentation or verbosity.
Integration within the document corpus
To earn the citation, the content must be perceived as authoritative and trustworthy (citation-worthiness). LLMs favour content from trusted domains with strong external signals such as quality backlinks and brand mentions from reliable sources. To strengthen this perception, it is crucial to create unique, research-based content — such as fresh data, direct personal experiences (first-hand experience), or expert insights — which AI alone cannot generate. In addition, the inclusion of author bios and the citation of primary sources or studies boosts the signals of experience, expertise, authoritativeness and trustworthiness (EEAT).
The use of entities (clear names of people, companies, products) helps LLM engines connect the page to relevant queries and topics, reinforcing topical relevance. Finally, readability is improved by the use of structured data (Schema.org) — labels that make explicit the nature of elements within the HTML code. While in the past SEOs focused only on a small number of types to enable Google’s rich results, the arrival of LLMs opens up new opportunities, given that the available schemas comprise over 800 types and 1,500 properties, useful for better understanding of content by AI-based engines.
Keeping content fresh and up to date with current statistics and information is another key factor, since LLMs appear to favour the most recent and reliable pages.
In summary, the GEO revolution demands a content strategy aimed at consolidating brand awareness and authority (leadership of thought). Optimisation must translate into the creation of content that is not only relevant but structured with care, in order to be cited at scale by Answer Engines — turning the potential loss of traffic linked to the drastic drop in CTRs into an opportunity to build relevance and cement the trust of the digital audience.
More articles in AI & SEO
Prompt Analysis: a new world to explore
Prompt analysis: a new world to explore Search analysis was born as a tactical tool for ranking on search engines. With the advent of chatbots and large language models, the raw material...
Read
The impact of AI Overview on People Also Ask answers
The impact of AI Overview on People Also Ask answers People Also Ask boxes first appeared in Google's results in the United States in 2015. After an initial phase of testing and...
Read
Google, Bing and GEO: who is right?
Google, Bing and GEO : who is right? For a while, as the debate among digital marketing professionals raged over the scope of GEO (Generative Engine Optimization) and AEO (Answer Engine Optimization)...
Read
Technical GEO: Discoverability, Accessibility and Readability
Technical GEO: Discoverability, Accessibility and Readability Rewriting the Rules of the Game in the AI Era The revolution sparked by Large Language Models (LLMs) is radically reshaping the dynamics of online search,...
Read
Google Search Console and Bing Webmaster Tools: Governing Access to Your Data
Google Search Console and Bing Webmaster Tools: Governing Access to Your Data Saying we need to pay attention to who can access our organic performance data and all the other information offered...
Read
From Keywords to Prompts and Back: Bing’s AI Performance Panel
From Keywords to Prompts and Back: Bing's AI Performance Panel In the article dedicated to query fan-out and reciprocal rank fusion we looked at the mechanism by which answer engines break down...
Read